L’architecture micro-services d’Affluences permet de déléguer la responsabilité de chaque fonctionnalité à un composant dédié et d’étaler la charge plus facilement. Il est donc nécessaire d’utiliser une interface de communication pour que ces services dialoguent avec les applications consommatrices. Nous utilisons soit une interface REST ou Graphql en fonction des cas d’usage. C’est cette dernière qui nous intéresse plus particulièrement dans ce billet.
Qu’est-ce que le langage GraphQL ?
Graphql est un langage de requête développé et maintenu par Facebook. Celui-ci permet notamment aux consommateurs de l’API de demander seulement les champs nécessaires à l’inverse d’une API REST qui expose un schéma prédéfini. Il est par exemple possible avec cette technologie d’effectuer une seule requête HTTP avec différentes entités là où il est généralement nécessaire de faire plusieurs appels lorsqu’il s’agit d’une API REST. Pour autant, cette souplesse peut également engendrer certains défis techniques comme le problème n + 1.
Qu’est-ce que le problème N + 1 ?
Le risque de l’implémentation de Graphql réside dans le fait qu’une demande peut générer N requêtes pour chaque relation enfant + 1 requête principale. Prenons un exemple : nous avons une bibliothèque avec plusieurs références de livres. Ces livres ont été notés par leurs acquéreurs. Nous voulons récupérer tous les livres de notre bibliothèque avec les notes attribuées à chacun d’entre eux.
query {
AllBooks {
id
title
note {
value
}
}
}Requête GraphQL pour récupérer tous les livres de notre bibliothèque avec les notes attribuées
Imaginons que nous ayons 10 livres dans notre bibliothèque, on récupèrera les dix livres en une requête. Pour les notes, comme il s’agit d’un sous champ des livres, il faudra faire un appel à la source de données par livre. Cela nous donne donc 11 appels pour récupérer le résultat de notre recherche.
| | Nombre d’éléments | Appels à la source de données |
| Livres | 10 | 1 |
| Notes | 4/livres = 40 | 10 |
| Total | 50 | 11 |
Imaginons désormais que nous souhaitons récupérer le nom de chaque personne qui a attribué chaque note avec la requête suivante :
query {
AllBooks {
id
title
notes {
value
buyers {
name
}
}
}
}| | Nombre d’éléments | Appels à la source de données |
| Livres | 10 | 1 |
| Notes | 4/livres = 40 | 10 |
| Acheteurs | 40 | 40 |
| Total | 90 | 51 |
On peut rapidement voir que ce problème est de l’ordre de xn : plus nous aurons de relation multiple, plus nous aurons un arbre d’appels grandissant.
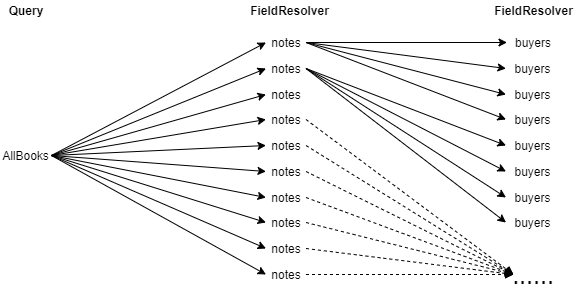
Implémenter un dataloader
Nous avons choisi d’implémenter la librairie dataloader pour répondre à ce problème. Le principe est de collecter tous les éléments nécessaires à tous les appels potentiels dans un cache temporaire afin de les combiner en un seul appel.
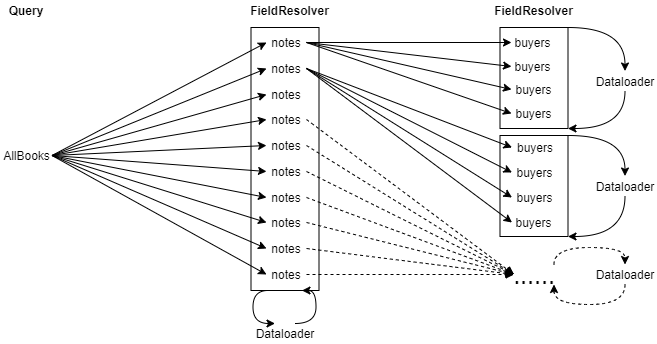
Cette première implémentation nous permet de régler le problème N + 1 puisque les appels sont groupés par field resolver. En revanche, les appels pour récupérer les acheteurs qui ont attribué une note ne sont toujours pas groupés, générant un volume toujours trop important d’appels à la source de données.
Surcharger le dataloader avec les requêtes GraphQL
Pour compléter la première solution, nous avons mis en place un système d’évènement pour déclencher le chargement du cache du dataloader.
Lorsque l’on reçoit une requête, nous faisons le premier appel à la source de donnée. Au fur et à mesure que les résultats sont reçus, nous incrémentons un compteur permettant de connaître le nombre d’éléments qui devront être ajoutés au cache lors de l’appel au dataloader. Lorsque nous recevons l’événement indiquant que toutes les informations nécessaires à la requête ont été ajoutées, nous déclenchons le chargement du cache du dataloader. Cette opération étant faite pour chaque sous entité, cela nous garantit un nombre d’accès à la source de données égal à la profondeur de la requête + 1, soit dans notre exemple 3 accès au lieu de 51 ! Dans les faits, nous implémentons cette approche à l’aide d’une annotation que nous référençons sur chaque field resolver, permettant ainsi à nos développeurs de l’ajouter facilement.
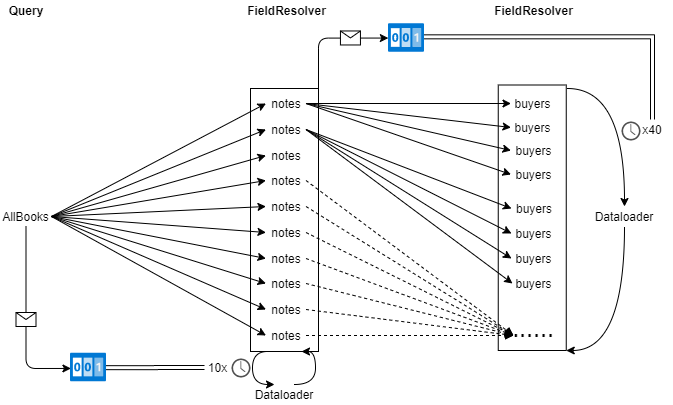
Cette approche nous permet de tirer partie au mieux des fonctionnalités apportées par le dataloader afin de soulager la charge sur notre infrastructure en limitant les accès aux sources de données au strict minimum pour accroître les performances de nos applications et supporter l’ajout permanent de nouveaux lieux à notre plateforme !